
Section 1: Introduction
What is Data Science?
Data science, a relatively new field, has emerged as a cornerstone of the modern technological landscape. It is the interdisciplinary study of extracting insights and knowledge from data using scientific methods, processes, algorithms, and systems. At its core, data science involves the collection, cleaning, exploration, analysis, and modeling of data to discover patterns, trends, and correlations that can inform decision- making.
In today’s data-driven world, data science has become indispensable across various industries. From healthcare and finance to marketing and manufacturing, organizations are leveraging data science to gain a competitive edge, improve efficiency, and drive innovation. By harnessing the power of data, businesses can make more informed decisions, optimize operations, and identify new opportunities.
The Importance of Data-Driven Decisions
In an era characterized by rapid technological advancements and increasing global competition, the ability to make informed decisions has become paramount for organizations. Data-driven decision-making, informed by insights derived from data analysis, offers a strategic advantage by:
- Enhancing decision quality: Data science provides a solid foundation for making evidence-based decisions, reducing the risk of errors and improving
- Optimizing resource allocation: By analysing data, organizations can identify areas where resources can be allocated more effectively, leading to improved efficiency and cost
- Identifying new opportunities: Data science can help uncover hidden patterns and trends that may lead to the discovery of new business opportunities or market
- Improving customer satisfaction: By analysing customer data, organizations can gain a deeper understanding of customer preferences and tailor their products and services to meet their
- Mitigating risks: Data science can be used to identify and assess potential risks, allowing organizations to take proactive measures to mitigate
The Data Challenge: Beyond the Volume
While the volume of data generated has grown exponentially in recent years, the true challenge lies not merely in the quantity but also in the complexity and diversity of data. Unstructured data, such as text, images, and audio, presents significant challenges for traditional data analysis techniques. Additionally, the increasing interconnectedness of data sources has made it difficult to integrate and analyse data from multiple systems.
Furthermore, the quality of data can be a major obstacle. Inaccurate, incomplete, or inconsistent data can lead to erroneous conclusions and undermine the reliability of data-driven insights. Addressing these challenges requires a combination of advanced data processing techniques, specialized tools, and expertise in data science.
Bridging the Gap: Data Science Techniques
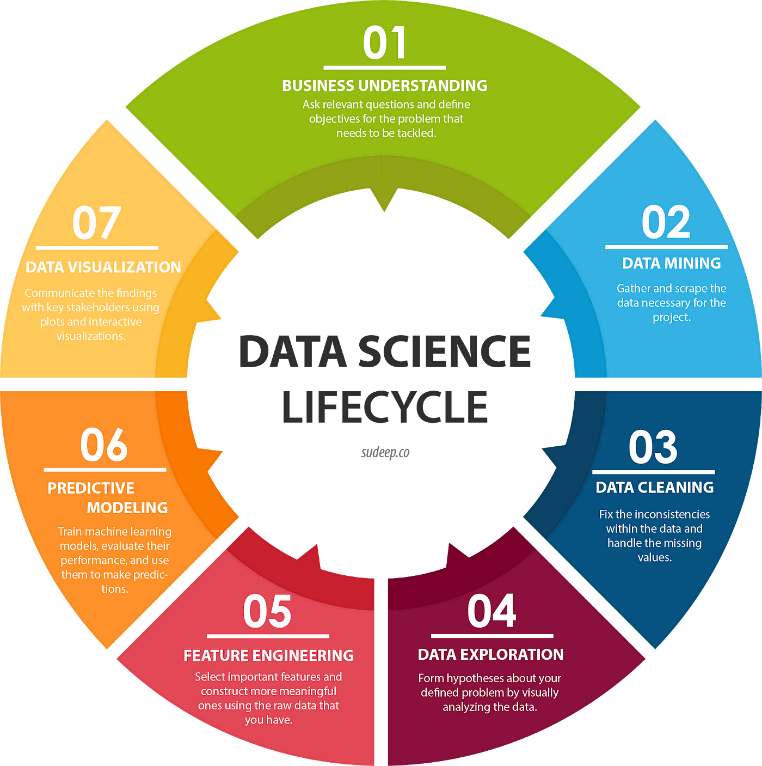
To overcome the challenges posed by complex and diverse data, data science integrates a variety of techniques and tools. These techniques can be broadly categorized into four key areas:
- Data acquisition: This involves collecting relevant data from various sources, including databases, APIs, and web scraping. Web scraping, in particular, has become a valuable tool for extracting data from websites, providing access to a vast amount of online
- Data cleaning and preparation: Once data is collected, it often needs to be cleaned and prepared for This involves tasks such as handling missing values, dealing with outliers, and formatting data consistently.
- Data exploration and analysis: Data exploration involves examining the data to identify patterns, trends, and This can be done using techniques like summary statistics, data visualization, and correlation analysis. Data analysis involves applying statistical and machine learning techniques to extract insights from the data.
- Data modeling and prediction: Data modeling involves building predictive models to forecast future outcomes or make predictions based on past This can be achieved using various machine learning algorithms, such as regression, classification, and clustering.
By effectively combining these techniques, data science can bridge the gap between raw data and actionable insights, enabling organizations to make informed decisions and drive innovation.
Section 2: Data Science Techniques - The Building Blocks of Insight
Data Acquisition
ata acquisition, the initial phase of any data science project, involves collecting relevant data from various sources. This data serves as the foundation for subsequent analysis and insights. Traditional methods of data collection often relied on surveys, questionnaires, and manual data entry. While these methods remain valuable in certain contexts, the increasing digitization of information has led to the emergence of modern techniques that enable efficient and scalable data acquisition.
Traditional Methods
Surveys and questionnaires are widely used to gather data directly from individuals. By designing well-structured surveys, researchers can collect information on a variety of topics, including demographics, opinions, preferences, and behaviours. However, surveys can be time-consuming and may suffer from response bias or low response rates.
Sensor data collection involves using specialized devices to measure physical quantities, such as temperature, humidity, pressure, or motion. Sensors are deployed in various environments, including factories, cities, and natural habitats, to gather real-time data on physical phenomena. This data can be used for a wide range of applications, from monitoring environmental conditions to optimizing industrial processes.
Modern Techniques for Diverse Sources
Modern techniques for data acquisition leverage the power of technology to collect data from a variety of sources. These techniques include:
Web Scraping
Web scraping, also known as web data extraction, is a powerful technique used to extract data from websites. By automating the process of navigating websites and extracting specific information, web scraping can efficiently gather large datasets that would be impractical to collect manually. This technique is particularly valuable for obtaining data that is not readily available through APIs or other structured formats.
APIs
Application Programming Interfaces (APIs) provide a structured way to interact with online services and retrieve data. APIs act as intermediaries, defining the rules and protocols for accessing and exchanging data between different systems. Many websites and platforms offer APIs that allow developers to programmatically access and retrieve data, such as social media posts, weather information, or financial data.
Database Access
Databases are organized collections of data that are stored and managed electronically. Accessing data stored in databases is a fundamental aspect of data acquisition. By querying databases using SǪL (Structured Ǫuery Language) or other database management systems, data scientists can retrieve specific information based on predefined criteria. Databases can be hosted on-premises or in the cloud, providing flexibility in data storage and access.
In addition to these methods, data can also be collected through sensors and IoT devices, which generate real-time data on physical environments. By combining various data acquisition techniques, data scientists can gather comprehensive and diverse datasets that are essential for conducting meaningful analyses and deriving valuable insights.
2.2. Data Wrangling - Preparing the Data Canvas
Data wrangling, also known as data munging, is a critical step in the data science process that involves cleaning, structuring, and transforming raw data into a usable format for analysis. This process is essential to ensure the accuracy and reliability of the data, as errors or inconsistencies can significantly impact the results of any analysis.
Key data cleaning tasks include:
- Handling missing values: Missing data can occur due to various reasons, such as data entry errors or incomplete To address this issue, data scientists often employ techniques like imputation, where missing values are replaced with estimated values based on other data points, or removal of rows with excessive missing data.
- Dealing with outliers: Outliers are extreme values that deviate significantly from the rest of the Identifying and addressing outliers is important to prevent them from skewing the results of analysis. Techniques for handling outliers include removal, capping, or transformation.
- Formatting data for consistency: Ensuring consistency in data formats and units is crucial for accurate analysis. This involves tasks such as standardizing date formats, converting units of measurement, and correcting inconsistencies in categorical
2.3. Data Exploration - Unveiling the Story Within
Data exploration is the initial phase of data analysis where the goal is to understand the data’s structure, characteristics, and patterns. By examining the data in detail, data scientists can gain valuable insights that inform further analysis and decision-making.
Key techniques used in data exploration include:
- Summary statistics: Calculating measures like mean, median, mode, standard deviation, and range provides a quick overview of the data’s distribution and central This helps identify potential outliers or unexpected patterns.
- Data visualization: Creating charts, graphs, and other visual representations of the data allows for easier interpretation and identification of trends, correlations, and Common visualization techniques include histograms, scatter plots, box plots, and bar charts.
By combining these techniques, data scientists can gain a deeper understanding of the data and identify potential areas for further investigation. This knowledge is essential for making informed decisions and guiding subsequent analysis steps.
2.4. Data Analysis - Extracting Knowledge
Data analysis is the stage where statistical and machine learning techniques are applied to uncover deeper insights from the cleaned and prepared data. This phase involves transforming raw data into meaningful information that can be used to answer specific questions or make informed decisions.

Descriptive Statistics
Descriptive statistics provide a summary of the data’s key characteristics. They help to understand the data’s distribution, central tendency, and variability. Common descriptive statistics include:
- Measures of central tendency: Mean, median, and mode represent the central value of the
- Measures of dispersion: Standard deviation, variance, and range measure the spread of the
- Frequency distributions: Histograms and bar charts visualize the distribution of categorical and numerical
Predictive Modeling
Predictive modeling involves building models to predict future outcomes or make classifications based on historical data. This technique is widely used in various fields, such as finance, marketing, and healthcare. Common predictive modeling techniques include:
- Regression analysis: Used to model the relationship between a dependent variable and one or more independent Linear regression is a common technique for modeling linear relationships, while logistic regression is used for predicting binary outcomes.
- Classification analysis: Used to predict categorical Techniques like decision trees, random forests, and support vector machines are commonly used for classification tasks.
- Time series analysis: Used to analyse data collected over time. Techniques like ARIMA (AutoRegressive Integrated Moving Average) and exponential smoothing are employed to forecast future
By applying appropriate data analysis techniques, data scientists can extract valuable insights from the data and address specific research questions or business problems.
Machine Learning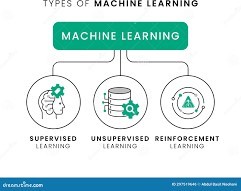
Machine learning, a subset of artificial intelligence, enables computers to learn from data and improve their performance on a specific task without being explicitly programmed. Machine learning algorithms can be used to identify patterns, make predictions, and automate tasks. Some common machine-learning techniques include:
- Supervised learning: In supervised learning, the algorithm is trained on a labeled dataset, where each data point has a corresponding target variable. Examples include regression analysis and
- Unsupervised learning: In unsupervised learning, the algorithm is trained on an unlabeled dataset and learns to identify patterns or clusters within the data. Examples include clustering and dimensionality
- Reinforcement learning: In reinforcement learning, the algorithm learns through trial and error by interacting with an environment. It receives rewards or penalties based on its actions and aims to maximize cumulative
Deep Learning
Deep learning is a subfield of machine learning that utilizes artificial neural networks with multiple layers. These networks are inspired by the structure of the human brain and can learn complex patterns and features from large datasets. Deep learning has achieved remarkable success in various domains, including:
- Image recognition: Deep learning models, such as convolutional neural networks (CNNs), have surpassed human performance in tasks like object detection, image classification, and image
- Natural language processing: Recurrent neural networks (RNNs) and transformer models have revolutionized natural language processing tasks, including machine translation, text summarization, and sentiment
- Speech recognition: Deep learning models can be used to accurately transcribe speech into text, enabling applications like voice assistants and speech-to-text
- Recommendation systems: Deep learning-based recommendation systems can provide personalized recommendations for products, movies, or other items based on user preferences and
Deep learning has the potential to solve complex problems that were previously intractable with traditional machine learning techniques. However, it requires large datasets and significant computational resources for training.
By combining statistical techniques, machine learning, and deep learning, data scientists can extract valuable insights from complex and diverse datasets. These insights can be used to inform decision-making, optimize processes, and drive innovation across various industries.
Section 3: Applications of Data Science
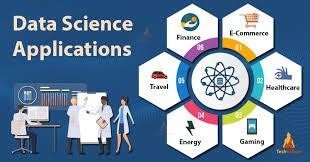
Healthcare :
Data science has revolutionized the healthcare industry by providing valuable insights and tools for improving patient outcomes, optimizing operations, and accelerating drug discovery. Here are some key applications of data science in healthcare:
Diagnosis and Disease Prediction
- Early disease detection: Data science algorithms can analyse medical images, such as X-rays, MRIs, and CT scans, to detect early signs of diseases like cancer, heart disease, and Alzheimer’s.
- Predictive analytics: By analysing patient data, including electronic health records, genetic information, and lifestyle factors, data scientists can predict the likelihood of developing certain diseases or experiencing adverse health
Personalized Medicine
- Tailored treatments: Data science can help identify optimal treatments for individual patients based on their unique genetic makeup, medical history, and lifestyle This personalized approach can improve treatment effectiveness and reduce side effects.
- Drug repurposing: By analysing existing drug data, data scientists can identify potential new uses for existing medications, accelerating drug discovery and reducing development
Drug Discovery and Development
- Target identification: Data science techniques can help identify new drug targets by analysing biological data, such as protein-protein interactions and gene expression
- Clinical trial optimization: Data science can be used to optimize clinical trials by identifying the most promising drug candidates, selecting appropriate patient populations, and monitoring patient
Population Health Management
- Disease surveillance: Data science can help track the spread of diseases and identify outbreaks early, enabling public health officials to take timely preventive
- Health disparities: By analysing population-level data, data scientists can identify health disparities and develop targeted interventions to improve health outcomes for underserved
Operational Efficiency
- Supply chain optimization: Data science can help optimize the healthcare supply chain by predicting demand for medical supplies, improving inventory management, and reducing
- Healthcare fraud detection: Data science algorithms can identify patterns of fraudulent activity in healthcare claims, helping to prevent financial losses and ensure the integrity of the healthcare
In conclusion, data science has the potential to transform healthcare by improving patient outcomes, reducing costs, and accelerating drug discovery. By leveraging the power of data, healthcare organizations can make more informed decisions, provide personalized care, and improve the overall health and well-being of populations.
Finance :
Data science has revolutionized the financial services industry, enabling institutions to make more informed decisions, manage risk more effectively, and improve customer experiences. Here are some key applications of data science in finance:
Fraud Detection
- Anomaly detection: Data science algorithms can identify unusual patterns and anomalies in financial transactions that may indicate fraudulent
- Real-time monitoring: By analysing transaction data in real-time, financial institutions can detect and prevent fraud before it causes significant
- Behavioural analytics: By analysing customer behaviour patterns, data scientists can identify deviations that may suggest fraudulent activity, such as unusual spending patterns or changes in account
Risk Assessment
- Credit risk assessment: Data science models can assess the creditworthiness of individuals and businesses by analysing a variety of factors, including financial history, income, and spending
- Market risk assessment: By analysing market data, data scientists can identify potential risks and assess the impact of market events on financial
- Operational risk assessment: Data science can help identify operational risks, such as system failures, fraud, and legal issues, by analysing internal and external
Algorithmic Trading
- High-frequency trading: Data science algorithms can analyse market data at high speeds and execute trades in milliseconds, taking advantage of small price
- Ǫuantitative trading: Data scientists develop quantitative models to identify trading opportunities based on statistical analysis of market
Customer Relationship Management (CRM)
- Customer segmentation: Data science can help financial institutions segment customers based on their demographics, behaviour, and preferences, enabling targeted marketing and personalized
- Customer churn prediction: By analysing customer data, data scientists can identify customers who are likely to churn and take proactive steps to retain
Regulatory Compliance
- Anti-money laundering (AML): Data science can help financial institutions identify suspicious activity that may be related to money
- Know Your Customer (KYC): Data science can automate the KYC process, ensuring compliance with regulatory requirements and reducing the risk of doing business with high-risk
Investment Management
- Portfolio optimization: Data science can help optimize investment portfolios by identifying the optimal allocation of assets based on risk and return
- Asset pricing: Data science models can be used to estimate the fair value of assets, such as stocks, bonds, and
Risk Management
- Stress testing: Data science can be used to simulate the impact of extreme market events on financial institutions, helping them assess their resilience and identify potential
- Insurance pricing: Data science can help insurance companies accurately price policies based on risk factors, ensuring fair pricing and
Data science has become an essential tool for financial institutions, enabling them to improve their decision-making, manage risk more effectively, and enhance their competitiveness. By leveraging the power of data, financial institutions can stay ahead of the curve and thrive in today’s rapidly evolving digital landscape.
Marketing and Sales :
Data science has revolutionized the way businesses approach marketing and sales by providing valuable insights into customer behaviour, preferences, and trends. Here are some key applications of data science in this area:
Customer Segmentation
- Identifying customer segments: Data science techniques can be used to identify distinct groups of customers based on their demographics, behaviour, and preferences. This allows businesses to tailor their marketing efforts to specific customer segments, increasing the effectiveness of their
- Customer profiling: By analysing customer data, businesses can create detailed profiles of individual customers, providing a deeper understanding of their needs and This information can be used to personalize marketing messages and offers.
Targeted Marketing
- Predictive analytics: Data science can be used to predict which customers are most likely to purchase a particular product or This enables businesses to target their marketing efforts to the most receptive audience, increasing the likelihood of conversions.
- Personalized marketing: By analysing customer data, businesses can create personalized marketing campaigns that resonate with individual This can lead to higher engagement rates and increased customer loyalty.
Sales Forecasting
- Demand forecasting: Data science models can be used to predict future sales trends, enabling businesses to optimize inventory levels, production planning, and resource
- Sales performance analysis: By analysing sales data, businesses can identify top-performing sales representatives and identify areas for improvement. This information can be used to provide targeted training and
Customer Relationship Management (CRM)
- Customer churn prediction: Data science can be used to identify customers who are at risk of churning, allowing businesses to take proactive steps to retain
- Customer lifetime value (CLTV) analysis: By analysing customer data, businesses can calculate the lifetime value of each customer, enabling them to prioritize their marketing efforts and focus on the most valuable
In conclusion, data science has become an essential tool for businesses in the marketing and sales industry. By leveraging the power of data, businesses can make more informed decisions, improve customer satisfaction, and drive revenue growth.
Section 4: Challenges and Opportunities

Data Privacy and Security
One of the major challenges facing data science is ensuring the privacy and security of sensitive data. As organizations collect and store increasing amounts of personal information, there is a growing risk of data breaches and unauthorized access. This is particularly relevant when using web scraping techniques, as data can be extracted from websites without explicit consent. Protecting sensitive data requires robust security measures, such as encryption, access controls, and regular audits.
Ethical Considerations
The use of data science and AI raises ethical concerns, particularly regarding bias and fairness. Data collection methods can introduce biases into datasets, leading to biased models that perpetuate existing inequalities. For example, if a training dataset is not representative of the population, the model may make discriminatory predictions. It is essential to address these ethical concerns by ensuring that data is collected and analysed in a fair and transparent manner.
Talent Shortage
Finding qualified data scientists and analysts can be a significant challenge for organizations. The demand for data science skills has surged in recent years, leading to a shortage of talent. This shortage can hinder organizations’ ability to leverage data effectively and achieve their goals. Addressing the talent shortage requires investing in education and training programs to develop a skilled workforce.
The Future of Data Science
The field of data science is rapidly evolving, with new technologies and techniques emerging continuously. Some of the emerging trends and opportunities in data science include:
- Advancements in web scraping: New tools and techniques are being developed to make web scraping more efficient and scalable, enabling organizations to access a wider range of data
- API integration: APIs are becoming increasingly prevalent, providing structured access to data from various sources. This makes it easier for data scientists to collect and integrate data from different
- Ethical AI: There is a growing focus on developing ethical AI that is fair, transparent, and accountable. This involves addressing biases in data and algorithms and ensuring that AI systems are used
- Edge computing: Edge computing involves processing data closer to its source, reducing latency and improving data privacy. This is becoming increasingly important as the volume of data generated continues to
As data science continues to evolve, organizations that can effectively leverage data will have a significant competitive advantage. By addressing the challenges and embracing the opportunities presented by data science, businesses can unlock new possibilities and drive innovation
Section 5: Conclusion
Recap of Key Points
Data science has emerged as a powerful tool for extracting valuable insights from data, enabling organizations to make informed decisions and drive innovation. Effective data collection and analysis are essential for harnessing the potential of data science.
Key points discussed in this blog post include:
- The importance of data-driven decision-making in today’s competitive
- The challenges associated with collecting, cleaning, and preparing data for
- The role of data science techniques, such as web scraping, APIs, and machine learning, in extracting insights from
- The ethical considerations and challenges related to data privacy, bias, and talent
- The potential of data science to transform various industries, including healthcare, finance, marketing, and
The Power of Data-Driven Decisions
By leveraging data science techniques, organizations can:
- Make informed decisions: Data-driven decisions are based on evidence and analysis, reducing the risk of errors and improving
- Optimize operations: Data science can help identify inefficiencies and optimize processes, leading to cost savings and improved
- Drive innovation: By uncovering hidden patterns and trends in data, organizations can identify new opportunities and develop innovative products and
- Improve customer satisfaction: Data science can help businesses better understand their customers and tailor their offerings to meet their needs, leading to increased customer satisfaction and
Unlocking the Potential
The field of data science is rapidly evolving, with new technologies and techniques emerging continuously. By exploring data science further and leveraging its potential, organizations can unlock valuable insights and drive innovation.
It is essential for individuals and organizations to invest in data science education and training to develop the necessary skills and knowledge. By embracing data science, businesses can position themselves for success in the data-driven era.

