
Introduction to Machine Learning Algorithms
Machine learning (ML) algorithms are the foundation of modern data science and artificial intelligence. They enable computers to learn from data without being explicitly programmed, allowing systems to improve over time as they are exposed to new information. These algorithms are crucial in solving many problems, from predicting trends to automating decision-making processes in healthcare, finance, e-commerce, and more industries.
The significance of ML algorithms lies in their ability to extract meaningful insights from large datasets, uncover patterns, and make predictions or decisions based on those patterns. For instance, they power recommendation systems on platforms like Netflix and Amazon, optimise supply chain logistics, and even assist in diagnosing diseases. The choice of the correct algorithm depends on the problem at hand, the nature of the data, and the desired outcome.
Popular Machine Learning Algorithms
1. Linear Regression
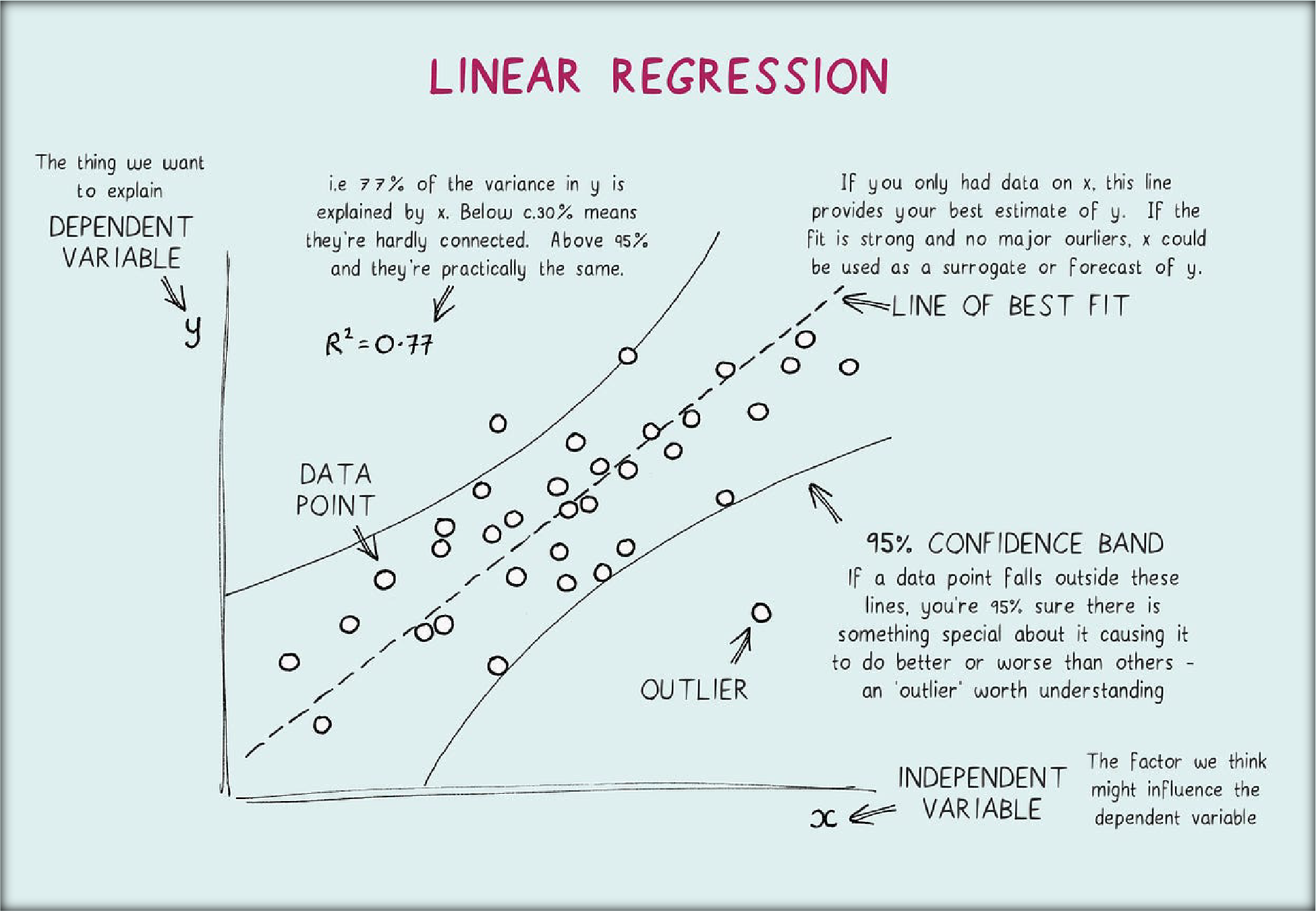
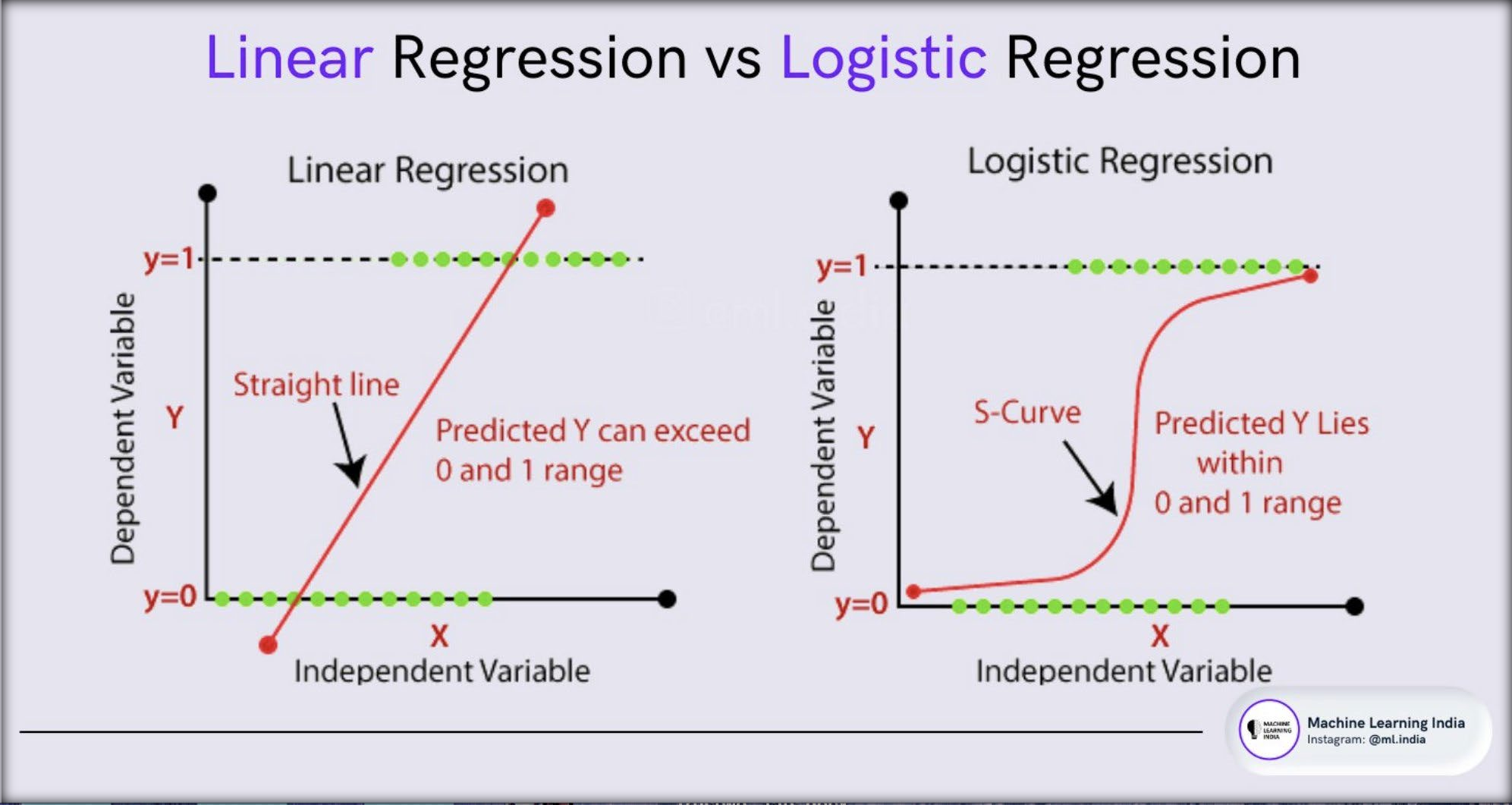
Linear Regression is a fundamental supervised learning algorithm that models the relationship between a dependent variable (target) and one or more independent variables (features). The algorithm assumes a linear relationship between the variables and uses this to predict outcomes.
Use Cases
- Forecasting sales or revenue based on historical
- Trend analysis, such as predicting temperature changes over
- Estimating housing prices based on features like size, location, and
Advantages
- Easy to interpret and
- Computationally efficient, even with large
Limitations
- Assumes a linear relationship, which may not hold in many real-world
- Highly sensitive to outliers, which can skew
Example
Suppose a company wants to predict future sales based on TV, radio, and social media advertising budgets. Linear Regression can be used to determine how changes in ad spending influence sales
2. Logistic Regression
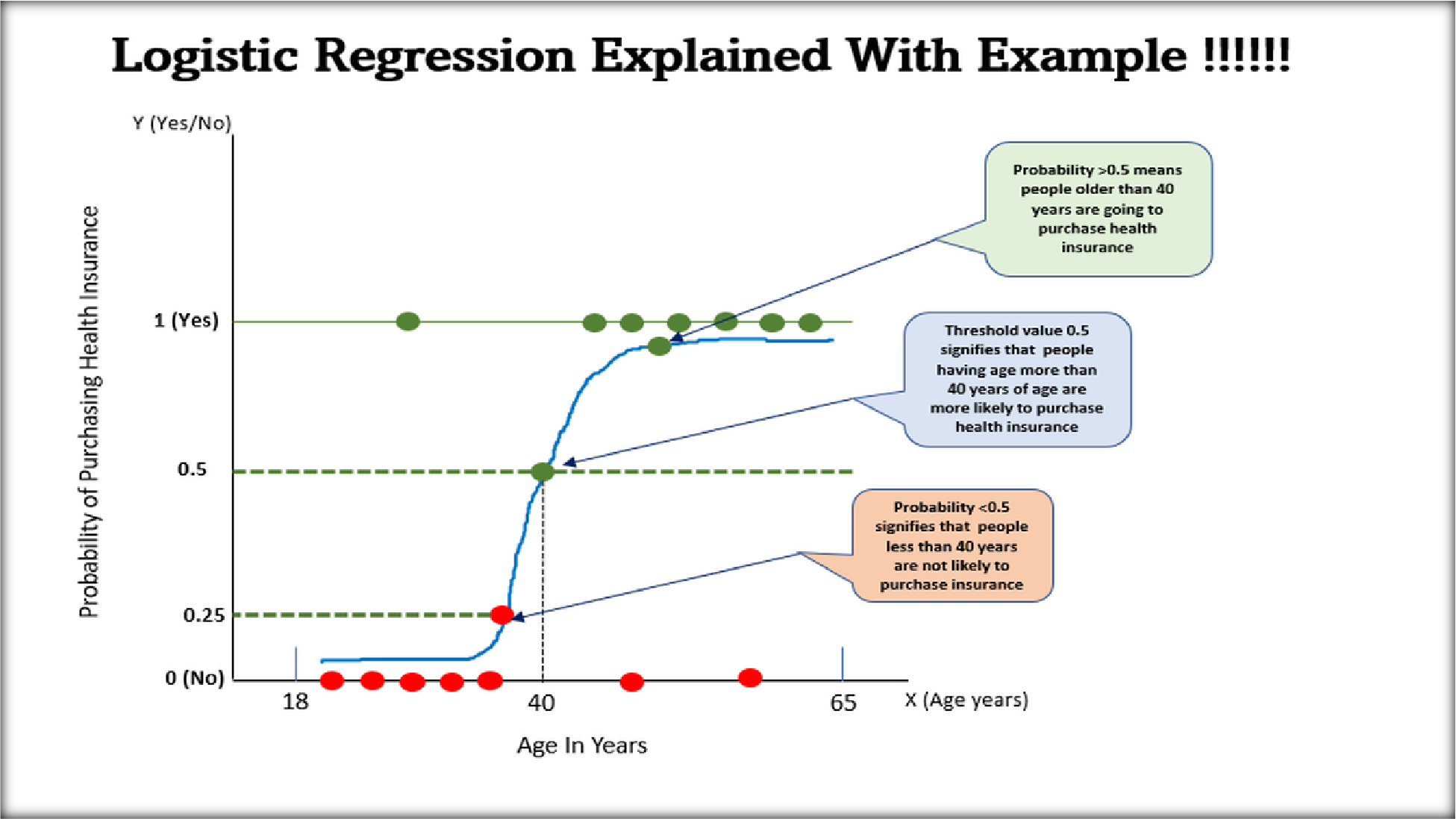
Logistic Regression is another supervised learning algorithm primarily used for classification tasks. It predicts probabilities that map data points to binary or multiple categories using a sigmoid function.
Use Cases
- Spam email detection (spam or not spam).
- Credit card fraud detection (fraudulent or legitimate transactions).
- Diagnosing diseases based on medical test results (e.g., diabetes: positive or negative).
Advantages
- Provides probabilistic interpretations, aiding in decision-
- Efficient and widely used for binary classification
Limitations
- Assumes a linear relationship between input variables and log-
- May struggle with complex, non-linear
Example
In healthcare, Logistic Regression can predict whether a patient has a particular disease based on symptoms and medical test results.
3. Decision Trees
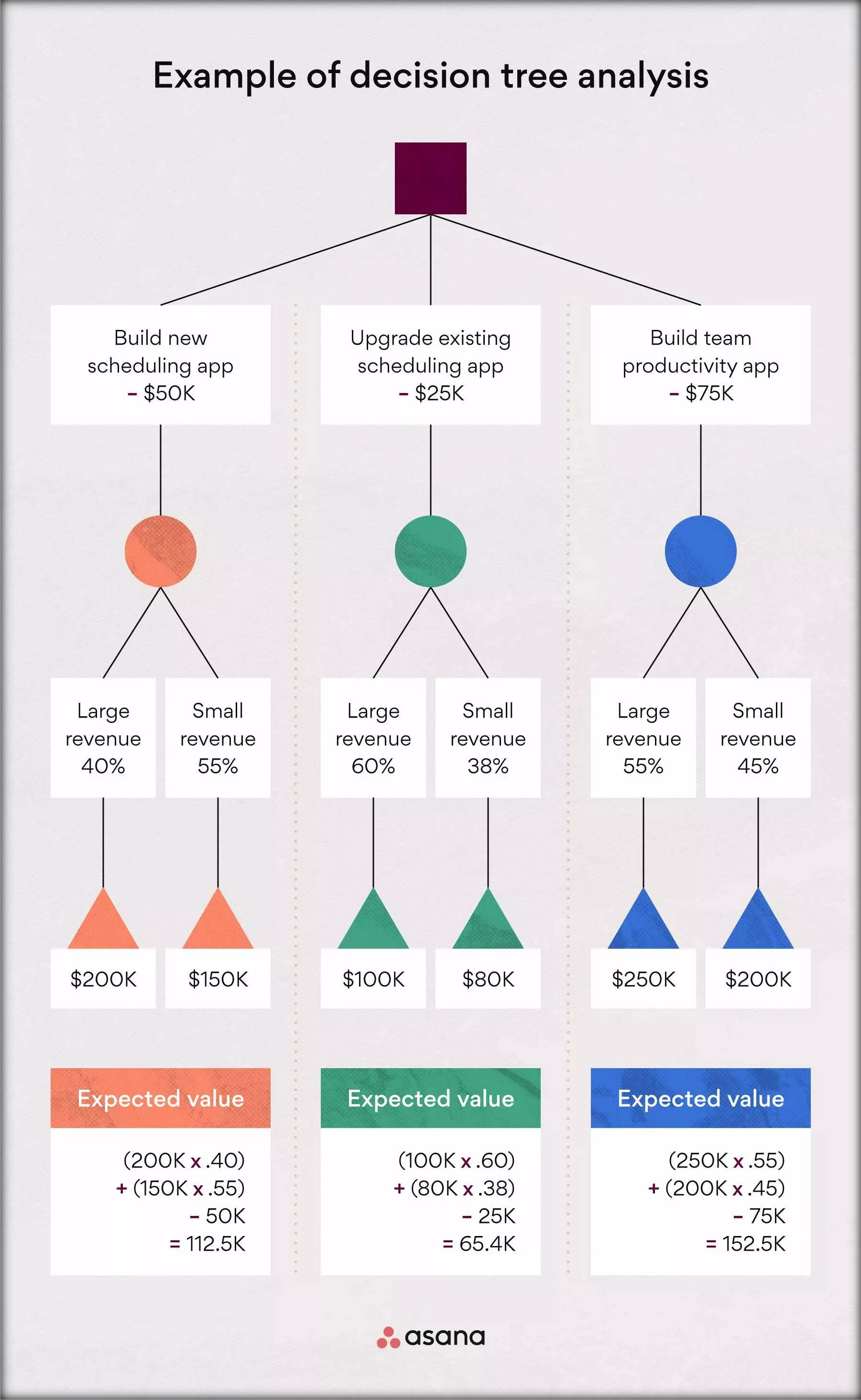
Decision Trees are non-linear algorithms that split data into subsets based on conditions at each node, creating a tree-like structure. They are intuitive and easy to visualise.
Use Cases
- Customer segmentation in marketing
- Predicting loan approvals based on applicant
- Diagnosing technical issues in machines based on error
Advantages
- Easy to interpret and understand, even for non-technical
- Handles both numerical and categorical
Limitations
- Prone to overfitting, especially with deep
- Sensitive to slight variations in data, which can lead to
Example
A bank can use a Decision Tree to decide whether to approve or reject loan applications by evaluating factors like credit score, income, and loan amount.
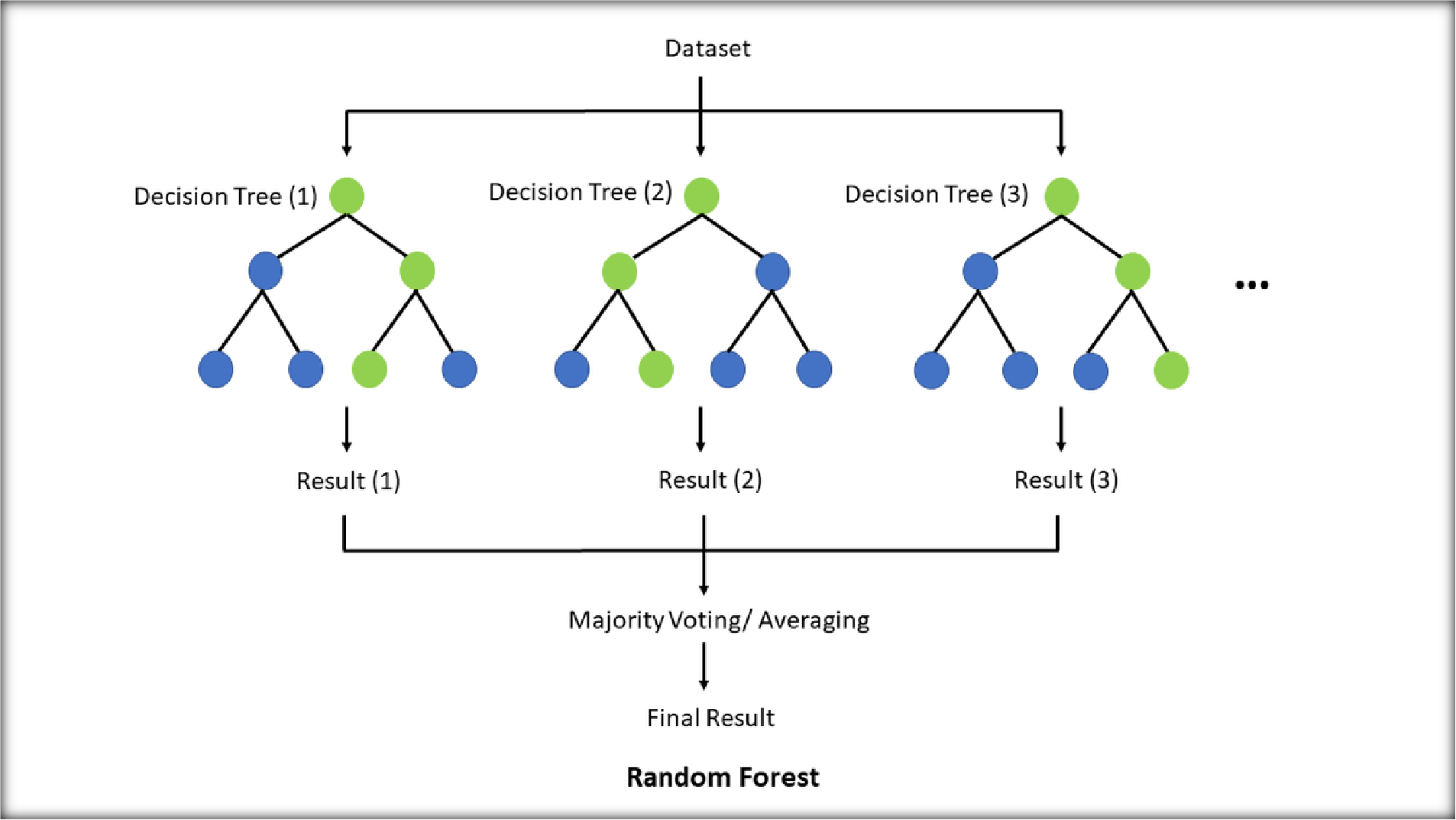
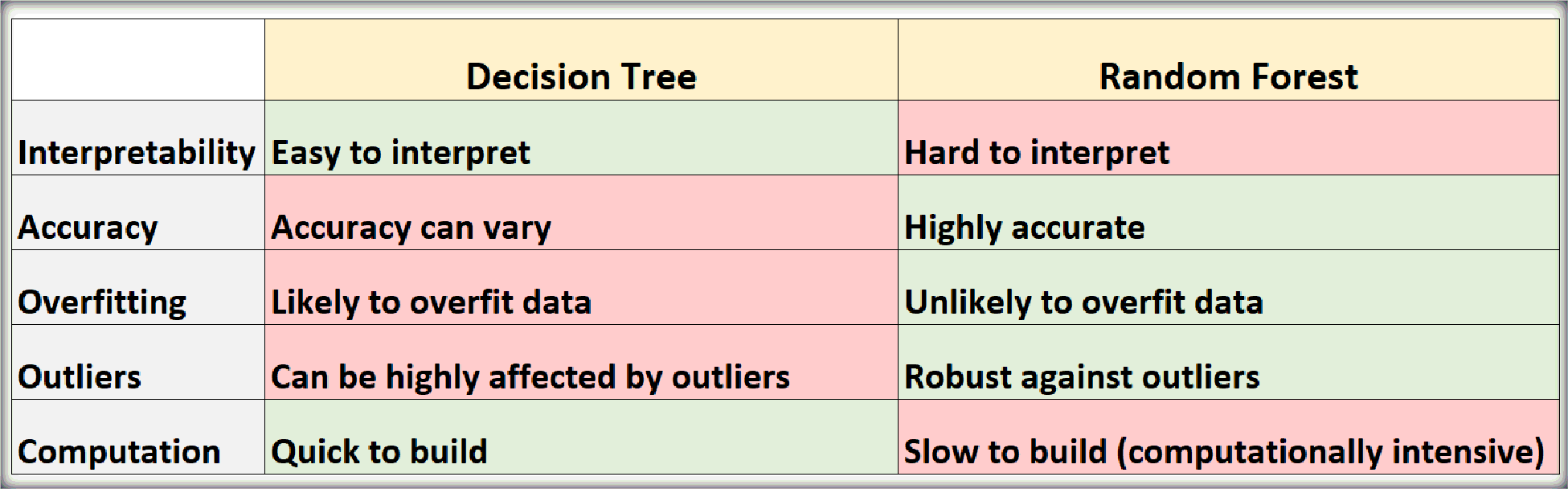
4. Random Forest
Random Forest is an ensemble learning method that builds multiple decision trees and merges their outputs for more accurate and stable predictions.
Use Cases
- Predicting stock market
- Detecting fraud in financial
- Classifying images in computer vision
Advantages
- Reduces the risk of overfitting compared to a single decision
- Handles missing data and large datasets
Limitations
- Computationally intensive due to the creation of multiple
- Difficult to interpret compared to individual decision
Example
E-commerce platforms use Random Forest algorithms to recommend products by analysing customer preferences and purchase history.
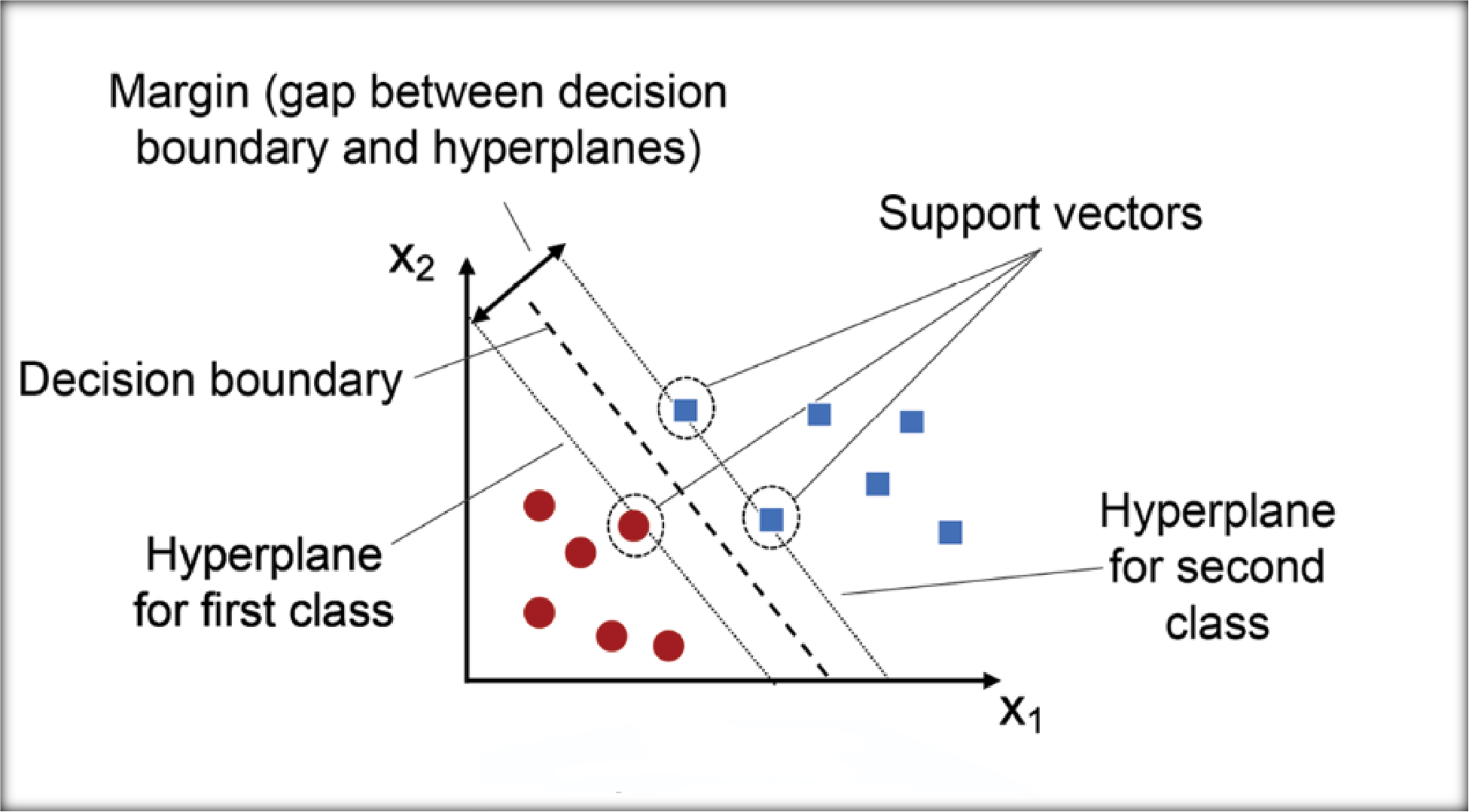
5. Support Vector Machines (SVM)
SVM is a robust supervised learning algorithm that works by finding the optimal hyperplane that separates data points into different classes.
Use Cases
- Text categorisation (e.g., classifying emails or news articles).
- Face recognition in
- Detecting anomalies in network
Advantages
- Effective in high-dimensional spaces and when the number of dimensions exceeds the number of data points.
- Robust to overfitting in low-noise
Limitations
- Memory-intensive and computationally
- Requires careful tuning of hyperparameters, such as the kernel and regularisation
Example
Based on experimental data, SVMs are often used in bioinformatics to classify proteins or genes.
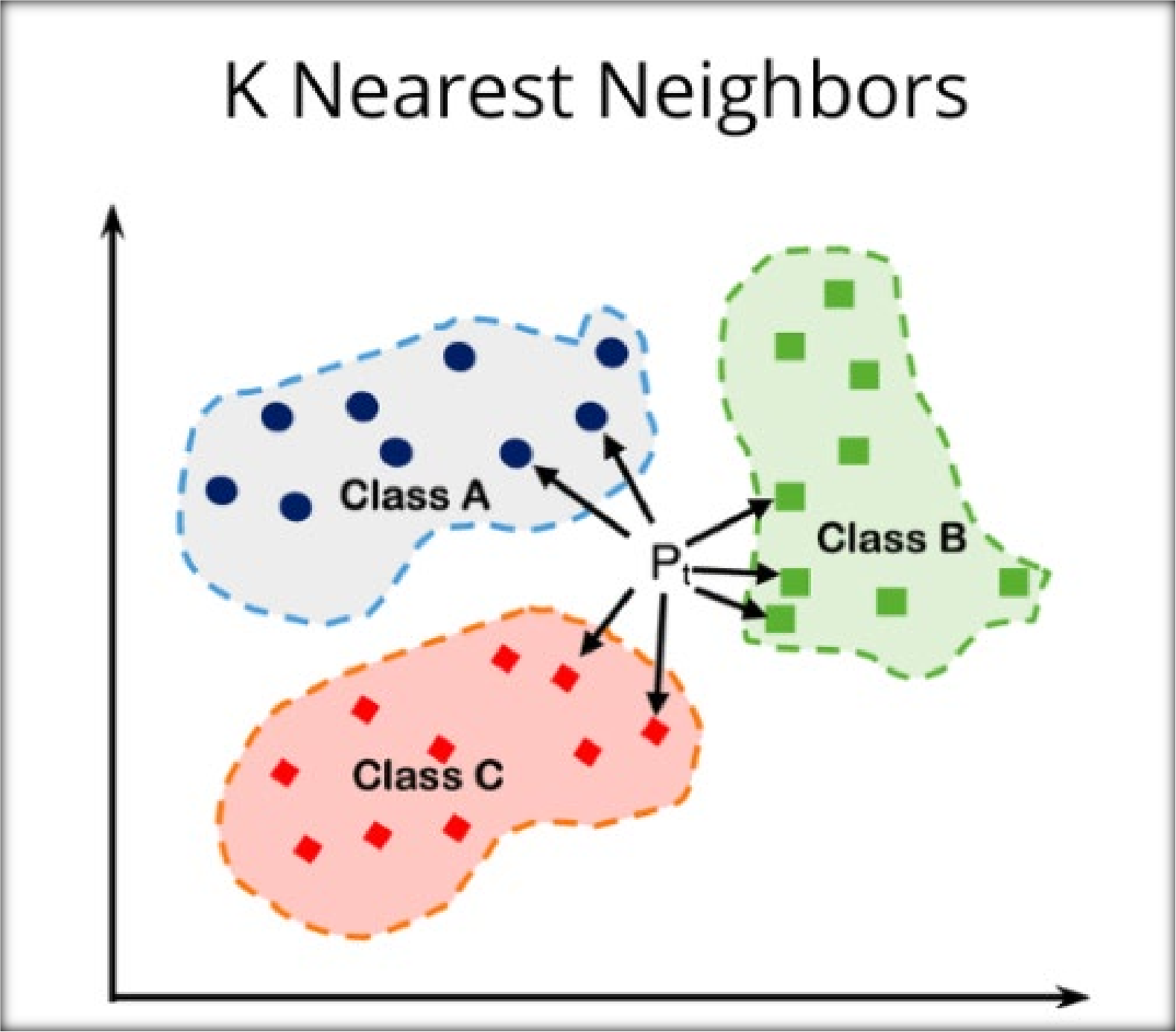
6. K-Nearest Neighbors (KNN)
KNN is an instance-based algorithm that classifies data points based on their proximity to other points in the feature space.
Use Cases
- Recommending similar movies or books to
- Classifying customer feedback as positive or
- Predicting diseases based on patient symptoms and historical
Advantages
- Simple and intuitive to
- Effective for non-linear
Limitations
- Computationally expensive during prediction since it requires scanning the entire
- Sensitive to the choice of the hyperparameter
Example
An online retail platform can use KNN to recommend products by comparing a user’s purchase history with similar customers.
Additional Considerations
Feature Scaling and Normalization
Algorithms like SVM and KNN are sensitive to the magnitude of feature values. Scaling techniques such as Min-Max normalisation or Standardization ensure that features contribute equally to the model’s predictions.
Model Evaluation Metrics
Evaluation metrics such as accuracy, precision, recall, F1-score, and ROC-AUC are critical to assessing ML models’ performance. These metrics provide insights into the model’s strengths and weaknesses, allowing for targeted improvements.
Overfitting and Underfitting Mitigation
Overfitting occurs when a model performs well on training data but poorly on unseen data. Regularisation techniques (e.g., L1, L2), cross-validation, and pruning effectively address this issue. Conversely, underfitting can be resolved by increasing model complexity or improving feature engineering.
Hyperparameter Tuning
Optimising hyperparameters can significantly enhance model performance. Grid and random search are standard techniques, while advanced methods like Bayesian optimisation and genetic algorithms can be used for complex models.

